
Your First AI Agent: Simpler Than You Think
The Complete Guide (with Code)

Hi folks,
This blog post is about a topic that’s close to my heart: AI Agents. I find them incredibly cool and useful!
After working on numerous AI Agent use cases and running a global hackathon, with LangChain with participants from all around the world, to create unique Agents, I took the time to write this post to make the concept of AI Agents easy to understand.
In this post, I’ll explain what AI Agents are and walk you through a simple example to help you build your first Agent easily using LangGraph.
Let’s start with some intro
The world of artificial intelligence is undergoing a profound transformation. For years, we've built specialized AI models - each designed to excel at a specific task. We have models that can write text, others that can analyze sentiment, and still others that can classify documents. These models are like skilled specialists, each performing their particular role with impressive expertise. But something has been missing: the ability to coordinate these capabilities, to understand context, and to make decisions about what to do next.
Think about how a human expert approaches a complex task. When a detective investigates a case, they don't just collect evidence in isolation. They interview witnesses and, based on what they learn, decide which leads to pursue next. They might notice a contradiction that sends them back to re-examine earlier evidence. Each piece of information influences their next steps, and they maintain a complete picture of the investigation in their mind.

AI Agents
This fragmented approach to AI created significant challenges. It placed a heavy burden on users to manage complex workflows, lost valuable context between steps, and lacked the adaptability needed for real-world tasks. Each model operated in isolation, like specialists who couldn't communicate with each other or adjust their work based on what their colleagues discovered.
This is where AI agents revolutionize the landscape. They represent a fundamental shift in how we approach artificial intelligence. An agent acts more like a skilled coordinator, orchestrating multiple capabilities while maintaining a holistic understanding of the task. It can make informed decisions about what to do next based on what it learns along the way, much like a human expert would.
What Makes an AI Agent Different?
To understand this transformation, let's examine how agents handle a specific task: analyzing a research paper about a new medical treatment.
A traditional AI approach fragments the analysis into isolated steps: summarizing the paper, extracting key terms, categorizing the research type, and generating insights. Each model performs its task independently, blind to the others' findings. If the summary reveals that the paper's methodology is unclear, there's no automated way to circle back and examine that section more carefully. The process is rigid, predetermined, and often misses crucial connections.
An AI agent, however, approaches the task with the adaptability of a human researcher. It might begin with a broad overview but can dynamically adjust its focus based on what it discovers. When it encounters significant methodological details, it can choose to analyze that section more thoroughly. If it finds intriguing references to other research, it can flag them for further investigation. The agent maintains a comprehensive understanding of the paper while actively guiding its analysis based on emerging insights.
This dynamic, context-aware approach represents the key difference between traditional AI and agents. Rather than executing a fixed sequence of steps, the agent acts as an intelligent guide through the analysis, making strategic decisions informed by everything it learns along the way.
The Architecture of Intelligence
At their core, AI agents are built on several fundamental principles that enable this more sophisticated approach to problem-solving.
First, there's the concept of state management🗂️. Think of this as the agent's working memory - its ability to maintain context about what it has learned and what it's trying to achieve. Just as a human investigator keeps the whole case in mind while examining individual pieces of evidence, an agent maintains awareness of its overall task while performing specific operations.
Then there's the decision-making framework⚖️. This isn't just about choosing between predetermined options - it's about understanding what tools and approaches are available and selecting the most appropriate ones based on the current situation. It's similar to how a detective might decide whether to interview another witness or analyze physical evidence based on what they've learned so far.

Finally, there's the ability to use tools🧰 effectively. An agent doesn't just have access to different capabilities - it understands when and how to use them. This is like a craftsperson who knows not just what tools they have, but when each one is most appropriate and how to combine them effectively.
Understanding LangGraph, a framework for AI- agents’ workflow
Now that we understand what AI agents are and why they're transformative, let's explore how to actually build one. This is where LangGraph enters the picture. LangGraph is a framework by LangChain that provides the structure and tools we need to create sophisticated AI agents, and it does this through a powerful graph-based approach.
Think of LangGraph as an architect's drafting table - it gives us the tools to design how our agent will think and act. Just as an architect draws blueprints showing how different rooms connect and how people will flow through a building, LangGraph lets us design how different capabilities will connect and how information will flow through our agent.
The graph-based approach is particularly intuitive. Each capability our agent has is represented as a node in the graph, like rooms in a building. The connections between these nodes - called edges - determine how information flows from one capability to another. This structure makes it easy to visualize and modify how our agent works, just as an architect's blueprint makes it easy to understand and modify a building's design.
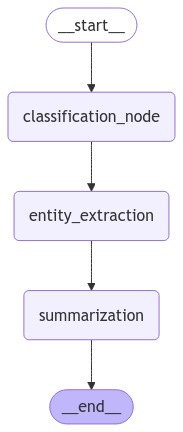
an example of a LangGraph agent (which we are just going to implement!)
Building Our First Agent: A Text Analysis System
Let's put these concepts into practice by building an agent that can analyze text documents. Our agent will be able to understand what kind of text it's looking at, identify important information within it, and create concise summaries. It's like creating an intelligent research assistant that can help us understand documents quickly and thoroughly.
You can find the entire code in my GitHub repo (8K⭐), along with 25 other tutorials that can help you build agents and get them production-ready:
Setting Up Our Environment
Before we dive into the code, let's set up our development environment properly. This will take just a few minutes and ensure everything runs smoothly.
Create a Virtual Environment First, open your terminal and create a new directory for this project:
bash
mkdir ai_agent_project cd ai_agent_projectCreate and activate a virtual environment:
bash
# Windows
python -m venv agent_env agent_env\Scripts\activate
# macOS/Linux
python3 -m venv agent_env source agent_env/bin/activateInstall Required Packages With your virtual environment activated, install the necessary packages:
bash
pip install langgraph langchain langchain-openai python-dotenvSet Up Your OpenAI API Key You'll need an OpenAI API key to use their models. Here's how to get one:
Create an account or log in
Navigate to the API Keys section
Click "Create new secret key"
Copy your API key
Now create a .env file in your project directory:
bash
# Windows
echo OPENAI_API_KEY=your-api-key-here > .env
# macOS/Linux
echo "OPENAI_API_KEY=your-api-key-here" > .envReplace 'your-api-key-here' with your actual OpenAI API key.
Create a Test File Let's make sure everything is working. Create a file named
test_setup.py:
python
import os
from dotenv import load_dotenv
from langchain_openai import ChatOpenAI
# Load environment variables
load_dotenv()
# Initialize the ChatOpenAI instance
llm = ChatOpenAI(model="gpt-4o-mini")
# Test the setup
response = llm.invoke("Hello! Are you working?") print(response.content)Run it to verify your setup:
bash
python test_setup.pyIf you see a response, congratulations! Your environment is ready to go.
Now when everything is ready, let's get started with building our agent. First, we need to import the tools we'll be using:
import os
from typing import TypedDict, List
from langgraph.graph import StateGraph, END
from langchain.prompts import PromptTemplate
from langchain_openai import ChatOpenAI
from langchain.schema import HumanMessageEach of these imports plays a crucial role in our agent's functionality. The StateGraph class will provide the foundation for our agent's structure, while PromptTemplate and ChatOpenAI give us the tools to interact with AI models effectively.
Designing Our Agent's Memory
Just as human intelligence requires memory, our agent needs a way to keep track of information. We create this using a TypedDict:
class State(TypedDict): text:
str classification:
str entities: List[str] summary: strThis state design is fascinating because it mirrors how humans process information. When we read a document, we maintain several pieces of information simultaneously: we remember the original text, we understand what kind of document it is, we note important names or concepts, and we form a concise understanding of its main points. Our state structure captures these same elements.
llm = ChatOpenAI(model="gpt-4o-mini",temperature=0)We then initialize the llm we want to use (in this case “gpt-4o-mini”, but you can use any llm that you want. if you work with Openai API you’ll need to create a private token on their website that will allow you to use it) with temperature =0. Temperature = 0 in LLMs means the model will always choose the most probable/likely token at each step, making outputs deterministic and consistent. This leads to more focused and precise responses, but potentially less creative ones compared to higher temperature settings which introduce more randomness in token selection.
Creating Our Agent's Core Capabilities
Now we'll create the actual skills our agent will use. Each of these capabilities is implemented as a function that performs a specific type of analysis.
First, let's create our classification capability:
def classification_node(state: State):
''' Classify the text into one of the categories: News, Blog, Research, or Other '''
prompt = PromptTemplate(
input_variables=["text"],
template="Classify the following text into one of the categories: News, Blog, Research, or Other.\n\nText:{text}\n\nCategory:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
classification = llm.invoke([message]).content.strip()
return {"classification": classification}This function acts like a skilled librarian who can quickly determine what kind of document they're looking at. Notice how we use a prompt template to give clear, consistent instructions to our AI model. The function takes in our current state (which includes the text we're analyzing) and returns its classification.
Next, we create our entity extraction capability:
def entity_extraction_node(state: State):
''' Extract all the entities (Person, Organization, Location) from the text '''
prompt = PromptTemplate(
input_variables=["text"],
template="Extract all the entities (Person, Organization, Location) from the following text. Provide the result as a comma-separated list.\n\nText:{text}\n\nEntities:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
entities = llm.invoke([message]).content.strip().split(", ")
return {"entities": entities}This function is like a careful reader who identifies and remembers all the important names, organizations, and places mentioned in the text. It processes the text and returns a list of these key entities.
Finally, we implement our summarization capability:
def summarization_node(state: State):
''' Summarize the text in one short sentence '''
prompt = PromptTemplate(
input_variables=["text"],
template="Summarize the following text in one short sentence.\n\nText:{text}\n\nSummary:"
)
message = HumanMessage(content=prompt.format(text=state["text"]))
summary = llm.invoke([message]).content.strip()
return {"summary": summary}This function acts like a skilled editor who can distill the essence of a document into a concise summary. It takes our text and creates a brief, informative summary of its main points.
Bringing It All Together
Now comes the most exciting part - connecting these capabilities into a coordinated system:
workflow = StateGraph(State)
# Add nodes to the graph
workflow.add_node("classification_node", classification_node)
workflow.add_node("entity_extraction", entity_extraction_node)
workflow.add_node("summarization", summarization_node)
# Add edges to the graph
workflow.set_entry_point("classification_node") # Set the entry point of the graph
workflow.add_edge("classification_node", "entity_extraction")
workflow.add_edge("entity_extraction", "summarization")
workflow.add_edge("summarization", END)
# Compile the graph
app = workflow.compile()
Congratulations we’ve just built an agent!
A reminder of how it looks:
This is where LangGraph's power shines. We're not just collecting different capabilities - we're creating a coordinated workflow that determines how these capabilities work together. Think of it as creating a production line for information processing, where each step builds on the results of the previous ones.
The structure we've created tells our agent to:
Start by understanding what kind of text it's dealing with
Then identify important entities within that text
Finally, create a summary that captures the main points
End the process once the summary is complete
Seeing Our Agent in Action
Now that we've built our agent, it's time to see how it performs with real-world text. This is where theory meets practice, and where we can truly understand the power of our graph-based approach. Let's test our agent with a concrete example:
sample_text = """
OpenAI has announced the GPT-4 model, which is a large multimodal model that exhibits human-level performance on various professional benchmarks. It is developed to improve the alignment and safety of AI systems.
additionally, the model is designed to be more efficient and scalable than its predecessor, GPT-3. The GPT-4 model is expected to be released in the coming months and will be available to the public for research and development purposes.
"""
state_input = {"text": sample_text}
result = app.invoke(state_input)
print("Classification:", result["classification"])
print("\nEntities:", result["entities"])
print("\nSummary:", result["summary"])When we run this code, our agent processes the text through each of its capabilities, and we get the following output:
Classification: News
Entities: ['OpenAI', 'GPT-4', 'GPT-3']
Summary: OpenAI's upcoming GPT-4 model is a multimodal AI that aims for human-level performance, improved safety, and greater efficiency compared to GPT-3.
Let's break down what's happening here, as it beautifully demonstrates how our agent coordinates its different capabilities to understand the text comprehensively.
First, our classification node correctly identified this as a news article. This makes sense given the text's announcement-style format and focus on current developments. The agent recognized the hallmarks of news writing - timely information, factual presentation, and focus on a specific development.
Next, the entity extraction capability identified the key players in this story: OpenAI as the organization, and GPT-4 and GPT-3 as the key technical entities being discussed. Notice how it focused on the most relevant entities, filtering out less important details to give us a clear picture of who and what this text is about.
Finally, the summarization capability pulled all this understanding together to create a concise yet comprehensive summary. The summary captures the essential points - the announcement of GPT-4, its key improvements over GPT-3, and its significance. This isn't just a random selection of sentences; it's an intelligent distillation of the most important information.
Understanding the Power of Coordinated Processing
What makes this result particularly impressive isn't just the individual outputs - it's how each step builds on the others to create a complete understanding of the text. The classification provides context that helps frame the entity extraction, and both of these inform the summarization process.
Think about how this mirrors human reading comprehension. When we read a text, we naturally form an understanding of what kind of text it is, note important names and concepts, and form a mental summary - all while maintaining the relationships between these different aspects of understanding.
Practical Applications and Insights
The example we've built demonstrates a fundamental pattern that can be applied to many scenarios. While we used it to analyze a news article about AI, the same structure could be adapted to analyze:
Medical research papers, where understanding the type of study, key medical terms, and core findings is crucial Legal documents, where identifying parties involved, key clauses, and overall implications is essential Financial reports, where understanding the report type, key metrics, and main conclusions drives decision-making
Understanding Our Agent's Limitations
It's important to understand that our agent, while powerful, operates within the boundaries we've defined. Its capabilities are determined by the nodes we've created and the connections we've established between them. This isn't a limitation so much as a feature - it makes the agent's behavior predictable and reliable.
First, there's the matter of adaptability. Unlike humans who can naturally adjust their approach when facing new situations, our agent follows a fixed path through its tasks. If the input text contains unexpected patterns or requires a different analysis approach, the agent can't dynamically modify its workflow to handle these cases better.
Then there's the challenge of contextual understanding. While our agent can process text effectively, it operates purely within the scope of the text provided. It can't draw on broader knowledge or understand subtle nuances like cultural references or implied meaning that might be crucial for accurate analysis. (you can overcome this with an internet search component if the information can be found on the internet).
The agent also faces a common challenge in AI systems - the black box problem. While we can observe the final outputs from each node, we don't have full visibility into how the agent reaches its conclusions. This makes it harder to debug issues or understand why the agent might occasionally produce unexpected results. (an exception here is using reasoning models like GPT-o1 or DeepSeek R1 that show you the way it thinks, but yet you cannot control it)
Finally, there's the question of autonomy. Our agent requires careful human oversight, particularly for validating its outputs and ensuring accuracy. Like many AI systems, it's designed to augment human capabilities rather than replace them entirely.
These limitations shape how we should use and deploy such agents in real-world applications. Understanding them helps us design more effective systems and know when human expertise needs to be part of the process.
I'm trying to follow along with this tutorial but the formatting is off and python is picky about formatting. I've read your comment about "full code can be found in my repo" but it's not obvious where in the repo this code is. Care to provide a link to the .py file for this tutorial please?
My understanding of Agent is that it should be able to handle some complexity which may arise at run time. How is the above designed system different from a simple program which uses LLM to answer some questions? but in the overall flow the so called agent is a linear program flow. If you can elaborate that part