
Vision Transformers Explained
When Machines Learn to See

One of the most fascinating challenges in artificial intelligence has always been teaching machines to see and understand the world as we do. While convolutional neural networks (CNNs) dominated computer vision for many years, the introduction of Vision Transformers (ViT) in 2020 marked a significant shift in the field. Since their introduction, these transformers have proven to be a powerful alternative approach to computer vision, offering new ways to process and understand visual information. In this post, we'll explore how Vision Transformers work, their impact on the field, and why they've become such an important tool in modern computer vision.
Understanding Human Vision
Think about how you recognize a cat in a photo. You don't methodically scan the image pixel by pixel, checking for whiskers, pointy ears, and fur in isolation. Instead, you take in the whole scene at once, naturally picking up on how different parts of the image relate to each other. A cat's eye means more when you see how it fits with the nose, ears, and overall face shape. This holistic approach to vision, where relationships between different parts of an image matter just as much as the parts themselves, is exactly what makes Vision Transformers so powerful and interesting.
Before we dive deeper into Vision Transformers, let's appreciate why this new approach was needed. Traditional CNNs, while incredibly successful, process images in a somewhat rigid way. Imagine looking at a painting through a series of increasingly larger windows - that's essentially how CNNs work, building up from small details to larger features. But this approach can miss the forest for the trees, sometimes struggling to understand how different parts of an image relate to each other.
The Origins of Vision Transformers
The story of Vision Transformers emerges from the remarkable success of transformer architectures in natural language processing. When transformers were introduced in 2017 with the landmark "Attention is All You Need" paper, they revolutionized how we process sequential data, showing an unprecedented ability to grasp relationships between words in a sentence, no matter how far apart they might be.
For several years, this breakthrough remained primarily in the domain of language processing. Then, in 2020, researchers at Google Research and Ludwig Maximilian University of Munich asked a compelling question: "What if we could apply this same attention-based approach to images?" This led to the publication of "An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale," which introduced the Vision Transformer (ViT).

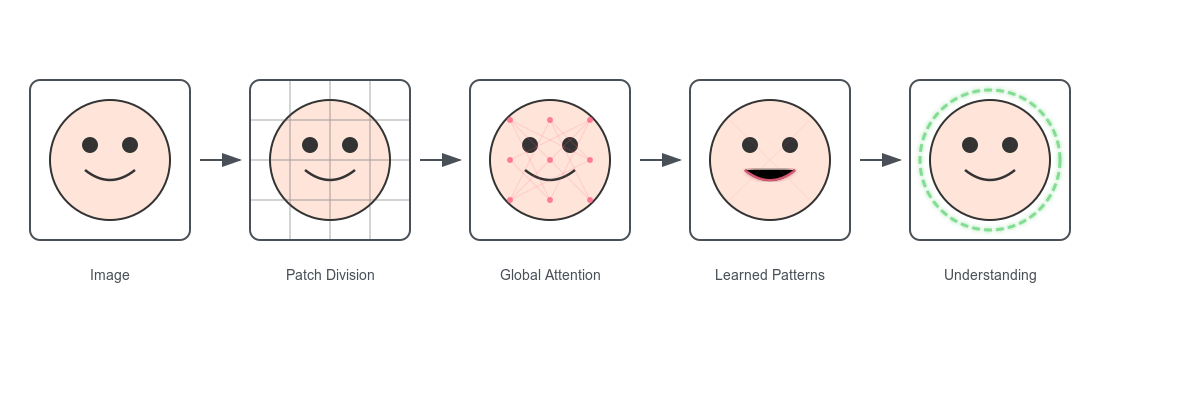
The key insight was brilliantly simple. Instead of processing words, ViT breaks down an image into a series of patches - essentially treating each 16x16 pixel patch as if it were a word in a sentence. Each patch becomes a "visual word" in the transformer's vocabulary. Just as a language transformer can understand how "not" at the beginning of a sentence affects the meaning of words at the end, a Vision Transformer can understand how an object in one corner of an image relates to objects in other corners.
This approach marked a significant departure from the CNN-dominated paradigm that had defined computer vision for nearly a decade. While CNNs excel at capturing local patterns through their hierarchical structure of convolutions and pooling, ViTs offered a fundamentally different way of understanding images - one based on global relationships and attention mechanisms.
Image Patch Processing
Let's break down how Vision Transformers actually "see" an image. Imagine you're trying to complete a jigsaw puzzle. Instead of looking at each piece in isolation, you constantly compare pieces to understand how they might fit together. You look for patterns that continue across pieces, colors that match, and shapes that complement each other.
This is remarkably similar to how Vision Transformers work. When presented with an image, they first divide it into patches - typically around 16x16 pixels each. These patches are like our puzzle pieces. But unlike a traditional CNN that would process each patch somewhat independently at first, the Vision Transformer immediately starts considering how each patch relates to every other patch in the image.
Each patch gets converted into a sequence of numbers (a vector) that represents its content - think of it as writing down a detailed description of each puzzle piece. But here's where it gets interesting: the transformer also adds information about where each patch is located in the original image. This is like numbering your puzzle pieces to remember their original positions. This combination of content and position information is crucial - it helps the transformer understand both what it's looking at and where everything is in relation to other elements.
Self-Attention Mechanism
The real magic of Vision Transformers happens in what's called the self-attention mechanism. This is where the transformer learns to focus on the most important relationships between different parts of the image. Think of it as having a conversation at a busy party - while you can hear many conversations happening around you, you focus your attention on the most relevant ones to understand what's being discussed.
In the context of an image, self-attention allows the transformer to dynamically decide which patches should "pay attention" to which other patches. When trying to identify a face, for example, the system might learn that patches containing an eye should pay special attention to patches that might contain another eye, or patches that contain a nose or mouth. This ability to create dynamic, content-dependent relationships between different parts of the image is what makes Vision Transformers so powerful.
Consider a practical example: identifying a person playing basketball. A Vision Transformer doesn't just recognize the person and the ball as separate entities - it can understand how they relate to each other. The position of the arms might influence how it interprets the ball's position, and vice versa. This holistic understanding leads to more robust recognition, especially in complex scenes where context matters.
But perhaps the most remarkable aspect of this attention mechanism is its flexibility. Unlike CNNs, which have fixed patterns for combining information from nearby pixels, Vision Transformers can adapt their attention patterns based on the content of each specific image. It's like having a detective who can dynamically change their investigation strategy based on the specific clues they find, rather than following the same procedure every time.
Training Process
The way Vision Transformers learn is fascinating and, in many ways, mirrors how humans develop visual expertise. Just as a child needs to see many examples of cats before being able to reliably identify them in different contexts, Vision Transformers require extensive training data to develop robust visual understanding. However, the way they learn from this data is unique.
Imagine teaching someone to identify birds. You wouldn't start by giving them a detailed manual of every feather pattern and beak shape. Instead, you'd show them many examples of different birds, letting them naturally learn to pick up on important features and patterns. Vision Transformers learn in a similar way, but with an interesting twist: they learn what to pay attention to entirely from the data itself.
The training process begins with what's called pre-training. During this phase, the transformer is shown millions of images and asked to solve a seemingly simple task: looking at a partial image and trying to predict the missing parts. It's like solving countless jigsaw puzzles where some pieces are hidden. Through this process, the transformer learns to understand the fundamental patterns and relationships that make up visual scenes.
What makes this approach particularly powerful is that the transformer isn't just memorizing specific images - it's learning general principles about how visual elements relate to each other. Just as a human who's good at jigsaw puzzles can tackle new puzzles they've never seen before, a well-trained Vision Transformer can understand new images by applying the principles it has learned.
Scaling and Efficiency
One of the most exciting aspects of Vision Transformers is how well they scale with more data and computing power. It's like having a student who not only learns from every example they see but actually gets better at learning as they see more examples. Traditional CNNs eventually hit a ceiling where adding more data or making the model bigger doesn't help much. Vision Transformers, on the other hand, continue to improve as they scale up.
However, this scalability comes with interesting challenges. Think of it like trying to have a conversation in an increasingly crowded room - the more people (or in our case, image patches) involved, the more difficult it becomes to manage all the potential interactions. Researchers have developed clever solutions to this challenge, such as having the transformer focus on only the most important relationships rather than trying to track every possible connection.
Real-World Applications
The impact of Vision Transformers extends far beyond academic research. Let's look at some real-world applications that showcase their unique capabilities:
Medical imaging has been revolutionized by Vision Transformers' ability to understand complex spatial relationships. When analyzing an X-ray or MRI scan, it's crucial to understand how different parts of the image relate to each other. A small anomaly might be more significant when considered in relation to surrounding tissues. Vision Transformers excel at this type of contextual analysis, often catching subtle patterns that might be missed by traditional approaches.
In autonomous driving, Vision Transformers are helping vehicles better understand their environment. Traditional systems might recognize individual elements like cars, pedestrians, and road signs separately. Vision Transformers can understand how these elements interact - for instance, how a pedestrian's position and movement relate to nearby vehicles and traffic signals. This holistic understanding leads to better prediction of how different elements in the scene might behave.
Even in more everyday applications like photo organization and editing, Vision Transformers are making an impact. They can understand the content and context of photos in ways that feel more natural and human-like. For instance, they can recognize not just that a photo contains people and a cake, but understand that it's a birthday celebration based on how these elements relate to each other.
Comparison with CNNs
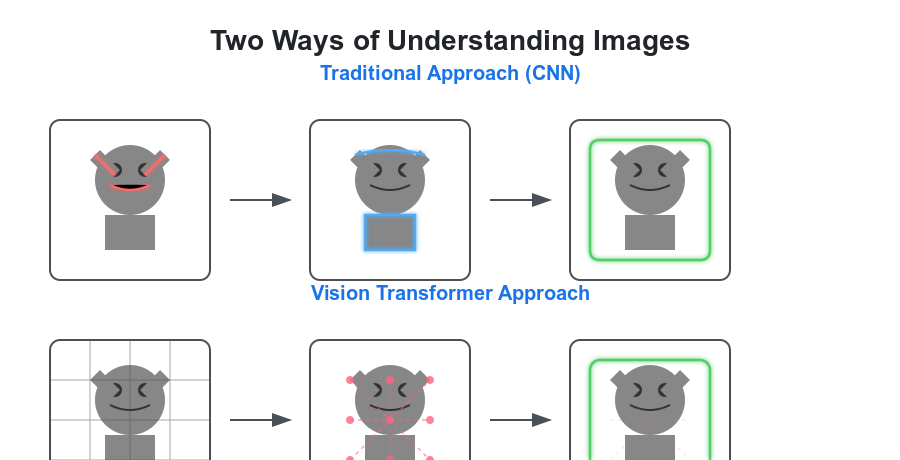
After several years of coexistence, the relationship between CNNs and Vision Transformers has become clearer. Rather than one architecture completely replacing the other, we've seen a more nuanced reality emerge where each approach has its distinct advantages and optimal use cases.
CNNs, with their decades of optimization and refinement, remain extremely efficient at capturing local patterns and hierarchical features. They're particularly well-suited for tasks that require strong local feature detection and where computational efficiency is paramount. The inductive biases built into CNNs - like translation invariance and local connectivity - make them naturally efficient at processing visual data.
Vision Transformers, by contrast, excel in scenarios where understanding global relationships and context is crucial. Their ability to model long-range dependencies and their flexible attention mechanisms make them particularly powerful for complex scene-understanding tasks. This global understanding has proven especially valuable in applications like medical imaging, where subtle relationships between distant parts of an image can be clinically significant.
The most successful modern approaches often combine both architectures, leveraging their complementary strengths. Hybrid models like ConvNeXt and Swin Transformers incorporate CNN-like hierarchical structures with transformer-style attention mechanisms. These hybrid approaches have shown that the future of computer vision likely lies not in choosing between CNNs and ViTs, but in thoughtfully combining their best aspects.
Evolution and Recent Developments
Since their introduction in 2020, Vision Transformers have undergone remarkable evolution. The original ViT model, while groundbreaking, had limitations - it required extensive pre-training on large datasets and was computationally intensive. However, the research community quickly began addressing these challenges, leading to a series of important improvements.
By 2021, we saw the emergence of more efficient architectures like DeiT, which showed that ViTs could be effectively trained on smaller datasets without the need for extensive pre-training. Swin Transformer, another key development, introduced a hierarchical structure that made ViTs more efficient and better suited for dense prediction tasks like object detection and segmentation.
The years 2022 and 2023 brought further refinements in efficiency and capability. Modern variants introduced sophisticated attention mechanisms that dramatically reduce computational overhead while maintaining or even improving performance. These weren't just incremental improvements - they were fundamental rethinkings of how attention can work more efficiently at scale.
The evolution has accelerated in 2024-2025, with several breakthrough developments reshaping the field. One significant trend has been the emergence of alternative architectures that move beyond traditional self-attention mechanisms. Structured state-space models and selective attention techniques have been incorporated into ViT-like architectures, substantially reducing memory and computational demands while maintaining high performance. These improvements have made ViTs more viable for real-world applications that process vast amounts of visual data.
Another key development has been the renaissance of hybrid approaches. While early ViTs deliberately moved away from convolutions, recent research has shown that incorporating lightweight convolutional layers can enhance local feature extraction while preserving the global reasoning power of self-attention. These hybrid models represent a more nuanced understanding of how different architectural components can complement each other.
The hierarchical architectures pioneered by models like Swin Transformer have been refined further, with new mechanisms that dynamically allocate computational resources based on task-specific needs. This adaptive approach allows models to focus processing power where it's most needed in an image, improving both efficiency and effectiveness.
Perhaps most significantly, we've seen ViTs become integral parts of sophisticated multimodal systems. Modern ViTs are deeply integrated with language and audio models, enabling joint vision-language reasoning where image understanding is directly conditioned on textual prompts. This has led to impressive advances in interactive image generation, visual question answering, and cross-modal retrieval. Recent improvements in contrastive learning and vision-language alignment have enhanced ViTs' ability to reason about images in increasingly structured and context-aware ways.
The latest developments have also focused on reducing dependency on massive labeled datasets. Advances in self-supervised learning have enabled ViTs to learn meaningful representations from unlabeled images. In contrast, improvements in few-shot and in-context learning techniques have made them more adaptable to new tasks with minimal supervision. This evolution mirrors the flexibility in large language models, suggesting a convergence in how different AI systems learn and adapt.
Challenges and Limitations
Despite their impressive capabilities, Vision Transformers aren't without their challenges. One of the most significant is their computational hunger - like a high-performance sports car, they need a lot of fuel (in this case, computing power and data) to perform at their best. This can make them impractical for some real-world applications where resources are limited.
There's also the challenge of interpretability. While Vision Transformers are powerful, understanding exactly how they make their decisions can be tricky. It's like having a brilliant detective who solves cases but struggles to explain their reasoning process to others. Researchers are actively working on tools and techniques to peek inside these black boxes and understand their decision-making processes better.
Another interesting limitation is their sensitivity to position information. Unlike humans, who can easily recognize an upside-down face or a mirrored image, Vision Transformers can sometimes struggle with such transformations unless specifically trained for them. This highlights the ongoing challenge of building AI systems that can match the flexibility and robustness of human vision.
Conclusion
Vision Transformers represent a fundamental shift in how machines understand visual information. By learning to see the world more like humans do - understanding context, relationships, and the big picture - they're opening new possibilities in artificial intelligence and computer vision.
As these systems continue to evolve, combining the best aspects of different approaches and becoming more efficient and practical, we're likely to see them become an increasingly important part of our technological landscape. From helping doctors diagnose diseases to enabling robots to better understand and interact with their environment, Vision Transformers are changing not just how machines see, but how they help us see the world in new ways.
This is a very instructive article. Scaffolded with familiar (even fun) analogies,it is a well planned out and guided tour of Vision models then and now. And its exceptional use of plain English and academic vocabulary make the content highly accessible. Even a fifth grader could understand it. 😉 Well done.
Excellent!