


Semantic Chunking: Improving AI Information Retrieval

Hello AI enthusiasts. Today, we’re exploring semantic chunking — a technique that’s making significant improvements in information retrieval. If you’ve been following developments in AI, you’re likely familiar with Retrieval-Augmented Generation (RAG). Let’s look at how semantic chunking can enhance RAG systems.
RAG Systems and Their Challenges
Retrieval-Augmented Generation has gained popularity for good reasons. It allows AI systems to answer questions by combining information retrieval with language generation. The standard RAG pipeline does this by ingesting data, retrieving relevant information, and using it to generate responses.
However, as data becomes more complex and queries more intricate, traditional RAG systems can face limitations. This is where semantic chunking comes into play.
Understanding Semantic Chunking
Semantic chunking is a method of dividing text or data into meaningful segments based on content and context, rather than arbitrary word counts or character limits.
Here’s how it typically works:
1. Content Analysis: The system examines the document to understand its structure and content.
2. Intelligent Segmentation: It divides the content into chunks based on semantic coherence — complete ideas or self-contained explanations.
3. Contextual Embedding: Each chunk retains information about its context within the broader document.
This approach helps preserve the meaning and relationships within the information, which is crucial for accurate retrieval and generation.
Limitations of Traditional Methods
Traditional chunking methods, while computationally efficient, have some drawbacks:
- They can split important concepts across multiple chunks.
- They often struggle to maintain context across divisions.
- They can lead to the retrieval of incomplete or disjointed information.
These limitations can affect the accuracy and relevance of AI-generated responses, especially when dealing with complex or nuanced information.
Semantic Chunking in Practice: An Example
Let’s consider a scenario where an AI system is analyzing legal documents. A query might be: “Summarize the key arguments related to fair use in the Smith vs. Jones copyright infringement case.”
A traditional system might return:
1. A chunk with the case introduction, cutting off mid-argument.
2. Another chunk from the middle of the fair use discussion, lacking context.
3. A concluding chunk that doesn’t connect to the main arguments.
In contrast, a system using semantic chunking would:
1. Identify the entire section on fair use arguments.
2. Keep related precedents and examples together with each argument.
3. Maintain the logical flow of the legal reasoning throughout the chunks.
The result is a set of information that better preserves the coherence and context of the original document, allowing for a more accurate and comprehensive response.
Another Example with a comparison to the vanilla method (where the data is an academic paper):
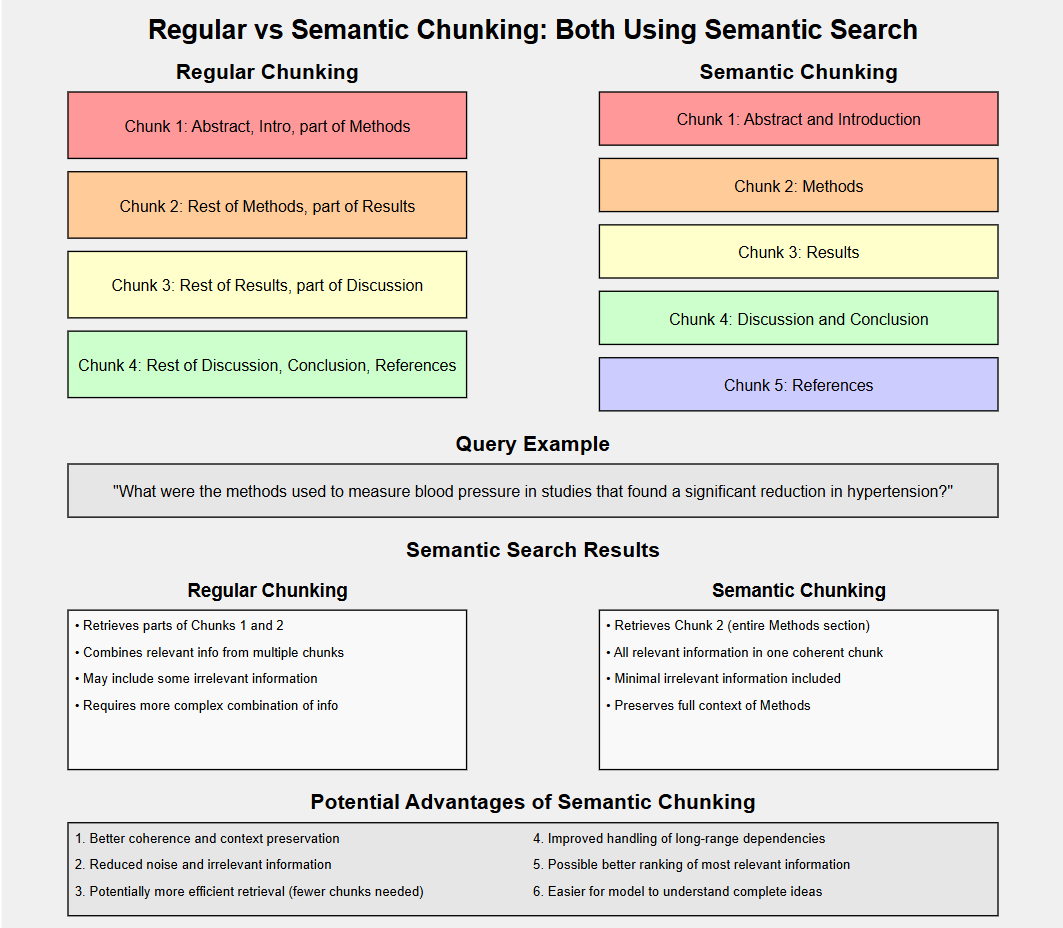
Implementing Semantic Chunking: Approaches
Several approaches to implementing semantic chunking show promise:
1. LLM-Powered Chunking:
— Uses large language models to identify semantic boundaries.
— Pros: Adaptable to diverse content types.
— Cons: Can be computationally intensive.
2. Rule-Based Semantic Segmentation:
— Employs linguistic rules and heuristics for logical breaks.
— Pros: Efficient for structured documents.
— Cons: Less flexible with varied content styles.
3. Hybrid Approaches:
— Combines statistical methods, machine learning, and rule-based systems.
— Pros: Balances efficiency with adaptability.
— Cons: More complex to implement.
The choice of method depends on factors such as the nature of your data, available resources, and specific requirements.
The Impact of Semantic Chunking on AI Systems
Integrating semantic chunking into RAG pipelines offers several advantages:
1. Better Context Preservation: Maintains the integrity of ideas and arguments.
2. Improved Retrieval Relevance: Returns results more closely aligned with query intentions.
3. Enhanced Handling of Complex Information: Particularly useful for long-form content and intricate subjects.
4. Increased Accuracy in AI Responses: Leads to more coherent and comprehensive outputs.
These improvements can result in more reliable AI systems capable of handling nuanced queries with greater precision.
Challenges and Future Directions
While semantic chunking offers benefits, it also presents challenges:
- Computational Requirements: More sophisticated analysis may require additional computational resources.
- Domain Adaptation: Effective chunking strategies may vary across different fields and content types.
- Balancing Granularity: Finding the optimal chunk size that preserves meaning without sacrificing efficiency.
The field continues to evolve, with ongoing research in areas such as:
- Multi-modal Semantic Chunking: Extending beyond text to understand and chunk other media types.
- Dynamic Chunking Systems: Adapting chunking strategies based on query context and content complexity.
- Integration with Advanced AI Models: Enhancing the synergy between semantic chunking and cutting-edge language models.
Conclusion: Advancing Information Retrieval
Semantic chunking represents a significant step forward in how AI systems process and understand information. By preserving the semantic structure of data, it enables more sophisticated, context-aware information retrieval and generation.
As we continue to develop AI capabilities, techniques like semantic chunking will play an important role in creating systems that can interact with complex information more effectively.
If you’re interested in implementing these techniques, check out my RAG techniques repository at https://github.com/NirDiamant/RAG_Techniques for practical examples and advanced approaches.
— -
If you found this article informative and valuable, and you want more:
Join our Community Discord
Connect with me on LinkedIn
Follow on X (Twitter)
🤗 And of course:
#SemanticChunking #RAG #AI #MachineLearning #InformationRetrieval