
HyDE: Exploring Hypothetical Document Embeddings for AI Retrieval
Link to implementation can be found at the end of this blog post

Information retrieval systems are constantly evolving. In this blog post, I’ll cover the approach called HyDE (Hypothetical Document Embeddings) which is pushing the boundaries of what's possible in zero-shot dense retrieval. Developed by Gao et al., HyDE combines the power of large language models with contrastive learning to perform effective retrieval without relying on relevance labels
We'll explore how HyDE works, examine its performance across various tasks and languages, and consider its potential impact on the field of AI-driven information retrieval.
What is HyDE?
HyDE, or Hypothetical Document Embeddings, is a method designed to enhance zero-shot dense retrieval in AI systems. Its innovation lies in a two-step approach:
1. Generate a hypothetical document using a large language model (LLM)
2. Encode this document using a contrastive learning model
This approach combines the strengths of generative language models and dense retrieval techniques.
To understand HyDE better, it's helpful to know what a contrastive learning model is. Contrastive learning is a machine learning technique where the model learns to differentiate between similar and dissimilar data points. In the context of document retrieval, a contrastive learning model would learn to represent documents in a way that similar documents are close together in the representation space, while dissimilar documents are far apart. This allows for efficient similarity-based retrieval (and this is actually how you create a custom embedding space).
How Does HyDE Work?
Let's break down the HyDE process step by step:
1. Query Input: The user submits a query or question.
2. Hypothetical Document Generation: An instruction-following LLM (like GPT-4o) creates a possible answer to the query. This "hypothetical document" captures relevance patterns but may contain factual errors.
3. Document Encoding: An unsupervised contrastively learned encoder (like Contriever) converts the hypothetical document into an embedding vector.
4. Similarity Search: The system uses this vector to find similar real documents in the corpus based on vector similarity.
5. Result Retrieval: The most similar real documents are returned as the search results.
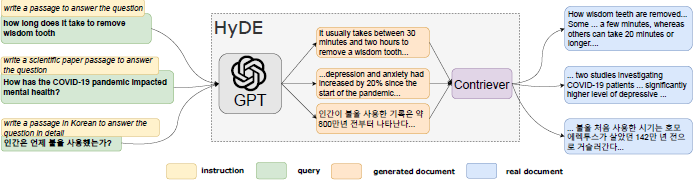
Examples from the Paper
To illustrate how HyDE works in practice, let's look at some concrete examples from the original paper:
Example 1: Web Search Query
Query: "how long does it take to remove wisdom tooth"
Hypothetical Document (generated by GPT-3):
It usually takes between 30 minutes and two hours to remove a wisdom tooth...
Real Document Retrieved:
How wisdom teeth are removed... Some ... a few minutes, whereas others can take 20 minutes or longer....
Example 2: Scientific Query
Query: "How has the COVID-19 pandemic impacted mental health?"
Hypothetical Document:
...depression and anxiety had increased by 20% since the start of the pandemic...
Real Document Retrieved:
... two studies investigating COVID-19 patients ... significantly higher level of depressive ...
Example 3: Multilingual Query (Korean)
Query: "인간은 언제 불을 사용했는가?" (When did humans use fire?)
Hypothetical Document:
인간이 불을 사용한 기록은 약 800만년 전부터 나타난다...
(Translation: Records of human use of fire appear from about 8 million years ago...)
Real Document Retrieved:
... 불을 처음 사용한 시기는 호모 에렉투스가 살았던 142만 년 전으로 거슬러간다...
(Translation: ... The time when fire was first used dates back to 1.42 million years ago when Homo erectus lived...)
These examples demonstrate HyDE's ability to generate relevant hypothetical documents and use them to retrieve similar real documents, even across different languages and domains.
Key Findings from the HyDE Paper
The authors conducted extensive experiments, and here are some of their key findings:
1. Comparison with Unsupervised Baselines: HyDE outperformed the unsupervised dense retriever Contriever across various tasks.
2. Performance vs Supervised Models: In many cases, HyDE showed performance comparable to fine-tuned retrievers, despite not using any relevance labels.
3. Multilingual Capability: HyDE demonstrated effectiveness across languages, including Swahili, Korean, and Japanese.
4. Task Versatility: The method performed well across diverse tasks such as web search, question answering, and fact verification.
Why HyDE Works
The effectiveness of HyDE can be attributed to several factors:
1. LLM Capabilities: By using an LLM to generate hypothetical documents, HyDE can capture complex relevance patterns and adapt to different query types.
2. Dense Retrieval Grounding: The contrastive encoder acts as a "lossy compressor," filtering out potential hallucinations from the LLM while retaining the core semantic information.
3. Task Flexibility: The instruction-based approach allows HyDE to adapt to various retrieval tasks without requiring task-specific training.
4. Query-Document Gap Bridging: The hypothetical document serves as an intermediary between the query and the document space, potentially capturing intent better than direct query encoding.
Challenges and Future Directions
While HyDE shows promise, there are some challenges and areas for future research:
1. Computational Resources: Generating hypothetical documents for each query can be resource-intensive, especially for large-scale applications.
2. LLM Dependence: The quality of results depends on the capabilities of the underlying LLM, which may vary across domains or languages.
3. Evaluation Complexity: Assessing the effectiveness of HyDE across diverse use cases requires careful consideration of various metrics and scenarios.
Future research might explore the following:
- More efficient generation techniques
- Integration with other retrieval methods
- Adaptation to multi-modal retrieval tasks
Conclusion
HyDE represents an innovative approach to zero-shot dense retrieval, leveraging the strengths of both large language models and contrastive learning. By generating hypothetical documents, it offers a way to capture relevance without explicit supervision, showing promising results across a range of tasks and languages.
As research in information retrieval continues, methods like HyDE open up new possibilities for creating more flexible and adaptable search systems. While it's not a silver bullet, HyDE provides an interesting direction for future work in this field.
What are your thoughts on HyDE? Can you think of specific applications where this approach might be particularly useful? Feel free to share your insights or questions in the comments!
→ Link to implementation and code tutorial ←
If you found this article informative and valuable, and you want more:
Join our Community Discord
Connect with me on LinkedIn
Follow on X (Twitter)
🤗 And of course:
#AI #InformationRetrieval #HyDE #MachineLearning #NLP
I was just looking for something like this yesterday! Do you know how this compares to generate potential questions from your documents in advance, then doing similarity search against the question?
It sounds like you need to use a specialized model (contriever) to generate the embedding of the hypothetical document. Can you not just use the same model that was used to generate the embeddings for the chunks of the original data?