


How AI Understands Us: The Secret World of Embeddings
Making Language Click with Numbers

Picture an ancient manuscript full of strange symbols. You know they hold meaning, but without a key to decode them, their secrets remain hidden. For years, this was how computers "saw" human language—as strings of unrelated symbols, impossible to comprehend.
Now, imagine assigning coordinates to each of those symbols, grouping similar ones together to reveal connections. This is the magic of embeddings: a way for artificial intelligence to understand language through math. But before we unpack this fascinating concept, let's see why it became necessary.
🤔 Why Are Embeddings Important?
Computers are good at working with numbers, but words pose a different challenge. When you read "cat," you might think of soft fur or a playful pet. For a computer, "cat" is just three letters: c, a, and t. It doesn’t understand how "cat" relates to "kitten" or "feline."
This gap made processing language difficult. Early solutions involved building dictionaries to connect related words. While this worked for simple cases, it couldn’t handle language’s complexity. Words like "bright" and "cold" have meanings that change with context, creating endless challenges.
Embeddings offered a solution by converting words, sentences, and even full texts into mathematical representations. This helps computers identify relationships and meanings more effectively by creating a new map of language relationships instead of relying on rigid dictionaries.
🗾 A New Map for Language
The breakthrough came with a fresh perspective: instead of listing all word relationships, why not teach computers to figure them out? What if we created a mathematical space where words with similar meanings naturally clustered together?
Think of it like a massive, multidimensional map:
Words that appear together often are placed in the same neighborhood.
Similar ideas are located near each other.
Different meanings of a word get their own zones.
Distances between words reflect their relationships.
This is what embeddings do: they convert language into numbers that preserve meaning. So, how do we create this map?
📜 A Quick History of Embeddings
Embeddings have transformed language processing, evolving dramatically over the years:
Word2Vec (2013): This model introduced the concept of word embeddings. It used two methods:
Skip-Gram: Predicts nearby words from a given word. For example, in "The cat sat on the mat," knowing "cat" helps predict words like "sat" and "mat."
Continuous Bag of Words (CBOW): Predicts a word based on its surrounding context. Here, "The," "sat," and "on" help predict "cat."
Word2Vec created spaces where words with similar meanings (e.g., "cat" and "dog") were placed close together.
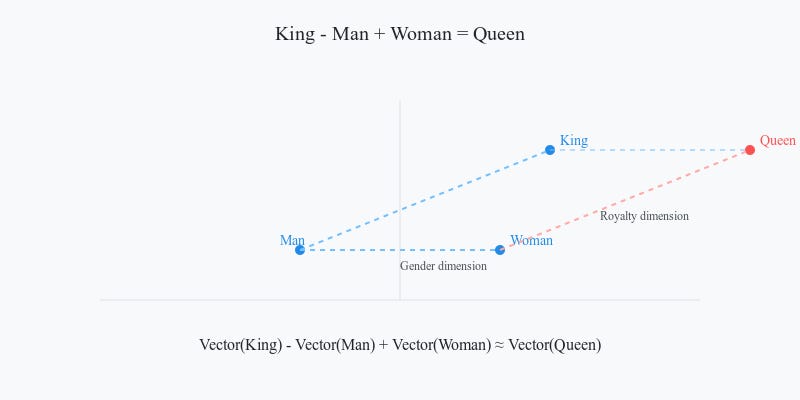
GloVe (2014): Short for Global Vectors for Word Representation, GloVe improved on Word2Vec by analyzing how often words co-occur across a dataset. This method revealed deeper relationships, such as the famous "king - man + woman = queen" analogy.
Transformers (2018): Models like BERT and GPT took embeddings further by focusing on context. Unlike earlier static embeddings, transformers adapt to how words are used in a sentence. For instance, "bank" in "river bank" and "financial bank" gets distinct representations.
These advances made it possible for AI to capture the intricacies of human language with remarkable accuracy.
🧠 How AI Learns (at Warp Speed)
The process mirrors how children learn language—but on a much larger scale. A child learns that "cup" and "mug" often mean the same thing and that "hot" and "cold" are opposites, all by observing patterns. Embedding systems do something similar but analyze millions of texts in minutes.
They notice patterns such as:
Words that often appear in similar contexts (e.g., "dog" and "cat" both "bark," "sleep," and "run").
Words frequently used together (e.g., "San" and "Francisco").
Words that can substitute for each other (e.g., "beautiful" and "gorgeous").
These patterns are then converted into numbers. Each word is represented by a vector—a long list of numbers designed to capture its meaning. Words with similar meanings end up with similar vectors.
🔢 Embedding Language at Every Level
Embeddings aren’t limited to words. They can represent sentences, paragraphs, or even entire documents. This flexibility is key for applications ranging from search engines to chatbots.
Why Embed Different Sizes?
Word Embeddings: Great for tasks requiring precise word relationships, like finding synonyms.
Sentence Embeddings: Capture the overall meaning of a sentence. Useful for tasks like question answering.
Paragraph or Document Embeddings: Capture broader themes, essential for summarization or categorization.

How Are Larger Texts Embedded?
Averaging Word Embeddings: Combine word vectors in a chunk. Simple but loses nuances like word order.
Recurrent Neural Networks (RNNs): Process text sequentially, capturing relationships over time. Good for longer chunks but struggles with very long texts.
Transformers: Analyze all words at once, capturing both local and global relationships. Highly effective for larger texts.
Pooling Techniques: Extract key features to summarize meaning, often used in transformers.
Practical Use Cases
Short Queries: Use word or sentence embeddings for semantic search.
Long Documents: Use paragraph embeddings for topic classification.
RAG Systems: Balance detail and efficiency by embedding medium-sized chunks (100-300 words).
🕺 The Magic of Dimensions
Embeddings work in high-dimensional spaces, and fascinating patterns emerge there. One famous example: subtract "man" from "king," add "woman," and you’re left with "queen." This isn’t magic—it’s the result of embedding systems learning relationships from data.
Other patterns include:
Capitals and countries.
Verbs and their tenses.
Categories and their members.
🤖 Why Context Matters
Language is tricky, and context changes meaning. Consider these examples:
"He drew a bow and fired an arrow."
"The violinist tightened the bow before playing."
"The actors took a bow after their performance."
Older systems treated "bow" as one thing. Modern systems generate context-specific embeddings, recognizing that "bow" means something different in each sentence.

🌍 Beyond Words
Embeddings extend far beyond language:
Proteins: Predict how drugs interact with proteins by embedding their structures.
Recommendations: Suggest products or content by embedding user preferences.
Images and Audio: Match pictures or melodies to text descriptions using embeddings.
For example, embeddings enable AI to find a song based on a humming melody or suggest relevant products by analyzing user behavior.
🌟 Everyday Applications
Embeddings power many tools you use:
Search Engines: Understand queries like "car won’t start" and link them to "engine troubleshooting."
Language Translation: Map meanings across languages to translate effectively.
Content Recommendations: Platforms like Netflix and Spotify use embeddings to suggest personalized content.
🏁 Wrapping Up
Embeddings are a cornerstone of AI’s ability to understand us. By turning language into numbers, they allow computers to capture meaning and relationships at an incredible scale.
Next time you search online or get a playlist suggestion, remember the math working behind the scenes. It’s not just about numbers; it’s about creating a digital version of understanding itself.
Excellent explanation
Thanks for the feedback! Happy you liked it :)