

Hey all, Today’s Blog post will explain to you the concepts behind image and video generation using AI.
Before we start today, I want to share with you some more details about the new initiative I’m working on:
I'm working really hard these days to create one place that will help people learn how to build AI agents and take them to production.
It’s going to be something HUGE, with the highest level of content quality, offering a comprehensive source of information, including the best tools available, and it will be updated frequently to keep this statement true.
Already, a bunch of great companies are in, and many more are showing interest - we are currently discussing collaborations.
If your company is creating technology that can assist people on their mission to create agents - at any step of the way, whether it’s creation, monitoring, optimization, UI, deployment, memory, or some parts that can be integrated within an agent, (and much more) - YOU WANT TO BE THERE.
If this is relevant for you, feel free to reach out and send me a DM on LinkedIn.
Where were we? Oh, okay, the image creation thing.
One of the most amazing developments in AI recently (recent years) has been diffusion models. These systems have changed how computers create images, making pictures that look more and more realistic. But how do they work? How can a computer start with random noise and end up with a detailed landscape, a realistic portrait, or an imaginary scene? In this post, I'll explain diffusion models, showing the clever way they learn to turn chaos into creativity.
Reverse Destruction
Imagine you're looking at a sandcastle on the beach. It's detailed and beautiful - towers with windows, a moat, even small flags on top. Now, imagine watching as waves slowly wash over it, gradually turning this structured creation back into smooth, plain sand. Diffusion models work in reverse: they learn to turn that smooth, plain sand back into the original sandcastle.
That's the main idea behind diffusion models. They learn to reverse a process of step-by-step destruction. But instead of sandcastles and waves, we're talking about images and noise.
Breaking Things Down
The training of diffusion models begins with a step that seems backward: teaching the model how to destroy images. We take good images and gradually add more and more random noise to them, step by step, until they become completely unrecognizable - just random static, like an old TV with no signal.
This forward process is like teaching someone exactly how paint slowly dissolves when dropped into water - how the clear edges blur first, how colors mix and fade, how patterns break apart. We're basically creating a detailed map of destruction.
At each step of this noise-adding process, we track exactly how the image changes, what details fade first, which structures last longest. The diffusion model learns to see the small differences between an image with a little bit of noise and the same image with slightly more noise.
Creation from Chaos
Once our model understands the destruction process, we give it a seemingly impossible challenge: start with pure noise and work backward. If adding noise is like dropping paint into water, we're now asking the model to look at cloudy water and figure out what drops of paint could have created that exact pattern of cloudiness.
This is where the real genius of diffusion models lies. When we ask them to generate an image, they start with completely random noise. Then, step by tiny step, the model applies what it learned about how images break down, but in reverse. It looks at the noisy image and predicts: "What would this look like with slightly less noise?"
It's like having a time machine for randomness. Each step removes a little bit of chaos, gradually revealing structure, then shapes, then details. The process typically takes dozens or hundreds of these noise-removing steps, each one bringing the image slightly closer to something recognizable.

Controlling the Output
So how do we control what kind of image comes from the noise? This is where guidance comes in. We can guide the diffusion model by giving it hints about what we want.
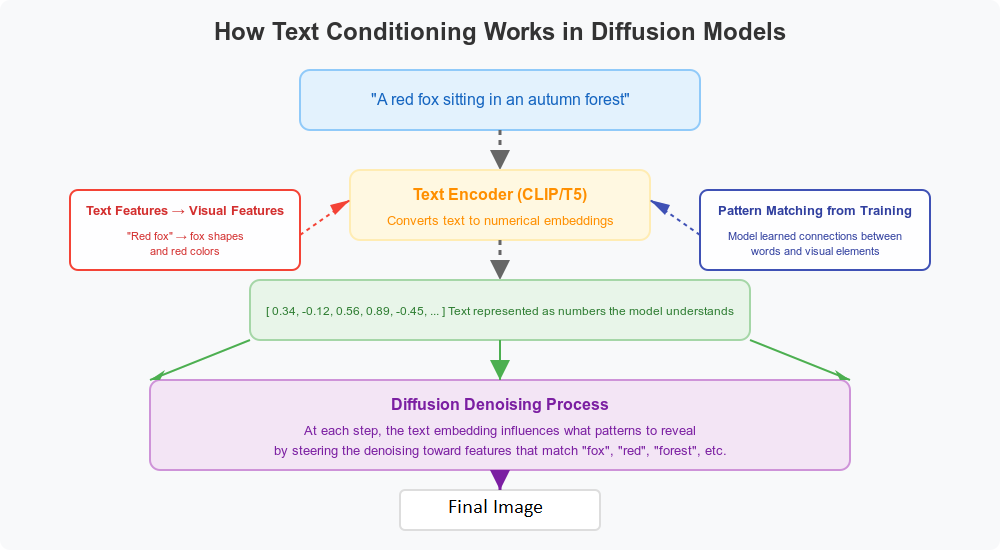
The simplest form is text guidance, where we provide a description like "a red fox sitting in an autumn forest." But how does the model actually understand this text and use it to shape the image?
The magic happens through what's called "conditioning." Modern diffusion models are paired with text encoders (like CLIP or T5) that convert your text description into a set of numerical values - a "text embedding." This embedding captures the meaning of your words in a form the diffusion model can work with.
During each denoising step, these text embeddings directly influence the model's decision making. At a technical level, the model has learned connections between certain text features and visual features during its training. When it's deciding how to remove noise at each step, it gives more weight to changes that align with the text embedding.
For example, if your prompt mentions "red fox," the model will favor denoising paths that develop fox-like shapes and reddish colors. It's like having a compass that constantly pulls the generation process toward the description you provided.
This is why the quality of your prompt matters so much. Vague prompts give weak guidance, while detailed, specific prompts provide stronger direction. The model isn't truly "understanding" your text in a human way - it's using statistical patterns it learned during training to connect text features with matching visual features.
It's similar to describing a destination to someone who's trying to find their way through fog. At each step, they use your description to decide which direction to move.
Diffusion vs GANs
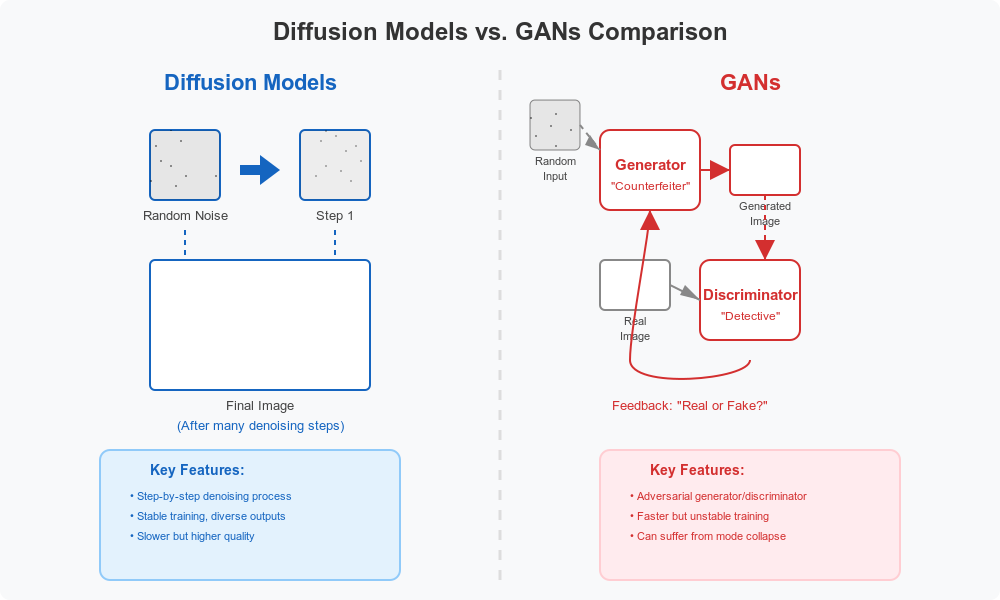
Before diffusion models became popular, Generative Adversarial Networks (GANs) were the leading technology for AI image creation. To understand what makes diffusion models special, it helps to compare them.
GANs work like a counterfeiter and detective locked in an endless contest. The generator tries to create fake images, while the discriminator tries to spot the fakes. Over time, the generator gets better at creating convincing images to fool the discriminator.
This competitive approach can create amazing results, but it's very difficult to train. GANs often get stuck generating only a limited variety of outputs. They're like students who memorize just enough to pass a test rather than truly understanding the subject.
Diffusion models, by contrast, learn in a more gradual, stable way. Instead of trying to generate a perfect image in one go, they learn the science of how images form, step by step. This approach tends to be more stable in training and often produces more varied results.
Mathematical Foundations
While the idea of reversing noise is powerful, the actual mechanics involve some elegant math. The forward process of adding noise follows what scientists call a diffusion process - hence the name "diffusion models."
The noise is added according to a carefully planned schedule, typically following what's called a Gaussian (normal) distribution. This schedule is crucial - too fast, and the model won't learn the subtle details of destruction; too slow, and training becomes inefficient.
The reverse process relies on learning what's called the "score function" - essentially, the direction in which an image with noise becomes more like a real image.
The training goal is to minimize the difference between the noise that was actually added and the noise that the model predicts was added. It's like learning to tell the difference between what a slightly blurry photo originally looked like and what noise caused the blurriness.
Real-World Applications
The impact of diffusion models goes far beyond creating pretty pictures for fun. Their applications are changing multiple industries:
Creative tools have been transformed by platforms like Midjourney, DALL-E, and Stable Diffusion, which have made image creation available to everyone. People without art training can now generate impressive images simply by describing what they want to see.
The film and game industries are using these models to speed up concept art creation, background generation, and character design. What once took artists days to sketch can now be generated in minutes, allowing for faster testing of visual ideas.
In scientific visualization, researchers are using diffusion models to show complex data in more understandable forms or to generate molecular structures with specific properties. This visual approach to data can reveal patterns that might be missed in number-based analysis alone.
Medical imaging has found valuable uses for diffusion models. They can improve low-resolution scans, generate practice data for diagnostic systems, and even help visualize how diseases might progress over time. This can lead to earlier diagnosis and better treatment planning.
Product designers are using these tools to quickly test visual concepts and explore variations they might not have considered otherwise. This speeds up the design process and expands the creative possibilities beyond what a single designer might think of.
Current Limitations
For all their power, diffusion models aren't perfect. They still struggle with certain aspects of images:
Logical consistency remains a challenge. These models sometimes generate images with impossible physics - reflections that don't match objects, or shadows pointing in wrong directions. They understand the parts of a scene but can miss how these elements should physically interact.
Text generation within images is particularly difficult. While diffusion models can create beautiful visuals, they often produce scrambled or nonsensical text when asked to include writing in their images. This limitation is gradually improving but remains noticeable.
Computing demands are significant. The step-by-step generation process means diffusion models are relatively slow compared to some alternatives. Generating a high-quality image can take seconds to minutes, though recent advances are rapidly improving efficiency.
Moving to Video Generation
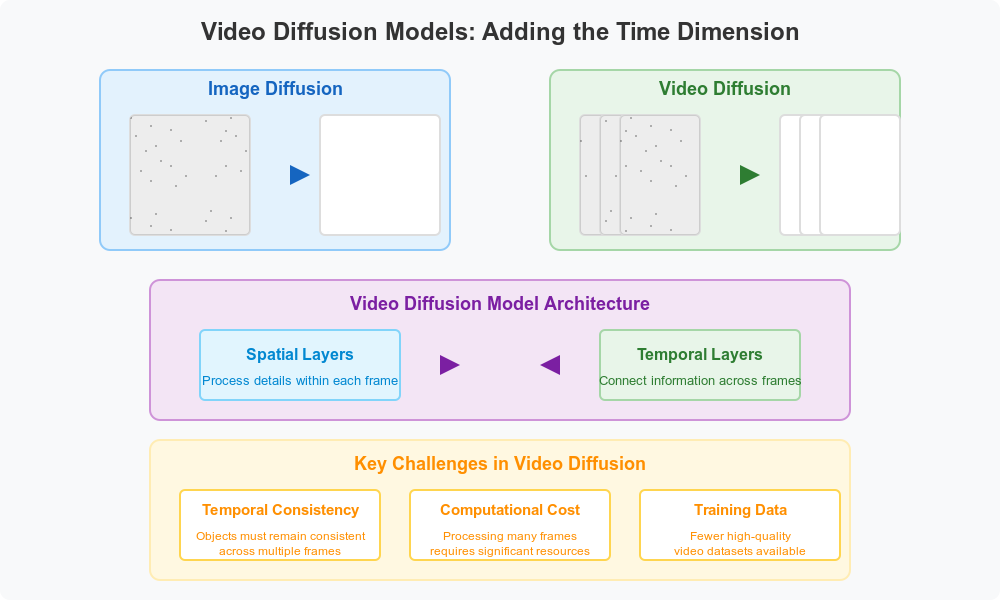
The ideas that make diffusion models so good for images are now being used to create videos too. Video diffusion models use the same noise-to-image process but add the element of time, creating a series of pictures that flow together while showing natural movement.
Creating videos with diffusion models brings new challenges beyond static images. The model must keep things consistent over time, making sure objects move naturally and backgrounds stay stable across frames. This needs a good understanding of how the real world works - objects don't randomly change appearance, and movements follow expected patterns.
Early video diffusion models built on image models by adding special layers to handle connections between frames. Models like VDM and Imagen Video use special 3D designs where some parts focus on details within each frame while others track how things change between frames. This approach helps keep everything looking connected while keeping the computing needs manageable.
One of the biggest hurdles for video diffusion models is how much computing power they need. Making even a few seconds of high-quality video means processing many frames, each with millions of tiny dots (pixels). To solve this, researchers have created smart methods like first making key images and then filling in between them, or working with compressed versions of the video.
Text-to-video systems like Sora, Pika, and Runway's Gen-3 have shown amazing abilities to create videos from written descriptions. These models can make short clips with realistic movement, complex scenes, and even camera movements - all guided by simple text prompts. Free and open alternatives like CogVideoX and Stable Video Diffusion are making this technology available to more people.
Beyond just making videos from text, these models allow exciting uses like bringing still images to life, editing videos (changing specific parts while keeping everything else consistent), and making short clips longer. These abilities are changing how people work in film production, marketing, education, and many other fields.
Future Possibilities
As we look ahead, diffusion models are just the beginning of a new era in creative AI. The line between human and machine creativity is becoming less clear, raising deep questions about the nature of art and imagination.
We're moving toward systems that can create not just static images but entire consistent worlds spanning multiple images, videos, sounds, and interactive elements. The creative possibilities are almost endless.
But perhaps the most exciting aspect is how these tools are becoming extensions of human creativity rather than replacements for it. The most interesting applications combine human creative direction with AI's ability to explore possibilities and handle technical tasks.
This was very interesting and well explained, thank you!