
Graph RAG Explained
Connecting the Dots in Retrieval-Augmented Generation

The recent buzz around Graph RAG and the way it's changing knowledge retrieval for AI models deserves careful look. While the excitement around knowledge graph-based systems is fair, understanding these steps forward requires going back to basics.
Graph RAG combines organized knowledge graphs with large language models to provide more aware, link-rich information. Whether it's a business helper answering hard questions or a research tool summing up insights across thousands of papers, the basic ideas stay the same. This post breaks down the key ideas behind Graph RAG, looking at why it's such a strong way to make AI systems smarter and how it has grown to fix the limits of basic RAG methods

Understanding Graph RAG
Imagine putting together a hard puzzle like a detective trying to solve a mystery. A regular AI helper might give you a stack of clue cards, each with a useful fact, but leave you struggling to see how they fit together. What if instead the helper gave you a map showing not just the clues but the lines of string linking them on a board? This is what Graph RAG does: it doesn't just find information, it connects the dots.
Regular Retrieval-Augmented Generation (RAG) fixes a big problem of large language models: they tend to make up facts or give answers not based in truth. It does this by letting the model quickly check a reference book before it answers, making sure the answer is up-to-date and true. But while helpful, regular RAG has limits that show up when questions get harder.
Think about the detective example again. Regular RAG would give you separate witness words, crime scene photos, and suspect details – all useful, but not connected. You would have to figure out yourself how these pieces fit together. Graph RAG, on the other hand, shows these links clearly – that Suspect A was seen near the crime by Witness B, or that the weapon belongs to Suspect C who knows the victim.
Link to my GitHub repo that contains a tutorial on GraphRAG: Repo Link
From RAG to Graph RAG
To understand Graph RAG, we should first look at how regular RAG works. There are two main steps:
Finding Step: The system turns a question into a search (often using vector matches to find similar text chunks). It pulls back a handful of the most fitting pieces of text from the knowledge source. Importantly, this step usually treats each piece of information on its own – it finds useful chunks but doesn't think about how they relate to each other.
Answer Step: The found text chunks are then given to the LLM along with the question. The LLM works with this added background and makes an answer, ideally using the chunks to stay true to facts.
While useful, this way has several key limits:
No Links Between Facts: Standard RAG treats found documents as separate pieces, missing the links between facts. For hard questions like "How are Company A and Company B connected?", regular RAG might find separate documents about each company but miss their link unless it's clearly stated in one chunk.
Small View Not Big Picture: RAG systems usually return the top few most fitting chunks. This works for specific questions but fails for "big picture" questions that need a view across an entire set of data. Asking "What are the main themes across all these research papers?" needs understanding the entire set, not just a few papers that mention "themes."
Missing Steps: When answering questions that need thinking through multiple steps, regular RAG can stumble. For a question like "What's the favorite food of Taylor Swift's cat?", it might find texts about Taylor Swift's pets and about cat foods, but miss the link that her cat is named Olivia and Olivia likes tuna.
Too Much Information: Regular RAG can feed the model a jumbled or too-large background. Key details can get lost in a pile of text, and long inputs risk being too big for the model to handle.
Understanding Knowledge Graphs
A knowledge graph is an organized way to show information where:
Nodes stand for things or ideas (e.g., a person, a company, a product, a health problem)
Edges show how they connect to each other (e.g., works at, partners with, causes, is the capital of)
This organized format is strong because it stores meaning: knowing Paris –(capital of)→ France tells you more than any single sentence of text; it gives a fact in a way that's easy to think with.
Knowledge graphs have been used widely in web search, business data management, and search engines. Google, for example, uses a knowledge graph to make its search results better with organized information about people, places, and things.
The power of knowledge graphs comes from their ability to show complex links and step-by-step rankings in a way computers can read. They let you move across and draw conclusions from linked data points, which is just what Graph RAG uses to make retrieval better.
Graph RAG fixes the limits of regular RAG by finding nodes and edges from a knowledge graph – in other words, a web of facts and their links.
How Graph RAG Works
Graph RAG implementations typically involve two phases: an indexing (graph-building) phase and a querying phase.
1. Indexing Phase
Before you can retrieve from a knowledge graph, you need to have one! This is like a detective setting up their investigation board before diving into a case. In the indexing phase, the system takes unstructured data (documents, web pages, PDFs) and extracts a structured knowledge graph from it, often using an LLM's ability to identify entities and relationships in text.
For example, the text "Taylor Swift's cat Olivia Benson loves tuna" would be processed to extract the triple: (Olivia Benson) –[favorite food]→ (tuna), and also link Olivia Benson as a cat owned by Taylor Swift.
By the end of this stage, you have a knowledge graph index: a network of entities connected by relationships, representing the content of your documents in a structured form.
Additionally, Graph RAG systems often perform community detection on the graph – finding clusters of closely related nodes. These clusters might represent a group of documents all about a similar topic. The system can then create a "community summary" for each cluster using an LLM, almost like chapter summaries for the knowledge graph.
2. Query Phase
When a user asks a question, Graph RAG has two main approaches:
Local Queries: For specific questions about particular entities ("Who is Barack Obama?"), the system identifies key entities in the query, finds the relevant nodes in the graph, and pulls in connected information. This is like the detective focusing on a specific suspect and gathering all related evidence.
Global Queries: For big-picture questions ("What are the main themes across these articles?"), Graph RAG uses community summaries and a map-reduce strategy:
Map step: The system asks each community summary if it has anything to contribute to the question
Reduce step: It aggregates these intermediate answers into a comprehensive response
This ensures that even with thousands of documents, nothing important is missed. It's like conducting a panel discussion where each expert on a subtopic gives their summary, and then you as the moderator synthesize a coherent conclusion.
Graph RAG vs Traditional RAG
Let's compare the key aspects of these approaches:

Applications
Where does Graph RAG really shine? Here are some key use cases:
Healthcare: In a medical setting, a Graph RAG system could link patient data with medical knowledge. When asked about similar patients and treatment results, it could trace links through symptoms, treatments, and outcomes, giving insights like: "Patients John and Anna had the same symptoms A and B. John was treated with Medicine X and got fully better, while Anna got Therapy Y with some improvement."
Money Analysis: A Graph RAG system could power an expert's helper, helping look into links between accounts or companies. When asked "What's the link between Company X and companies flagged for fraud?", it could walk a deal graph to find middle-man groups that connect them – links a text search might miss.
Legal Research: Law firms could use Graph RAG to move through the tricky web of cases, laws, and past rulings. A lawyer could ask "Has case A been brought up in any green law setting lately?" and the system would walk the citing graph, following links between cases and legal fields to find fitting past cases.
Business Knowledge Management: Companies with large document sets could use Graph RAG to answer hard questions that cross many departments or topics. Questions like "How did our way of handling product X change across teams?" would gain from the system's ability to link information across business walls.
You can see a nice, simple demonstration (tutorial) of Microsoft’s Graph RAG use in my RAG_Techniques repo 👉 Graph RAG demo
Benefits
What makes Graph RAG so strong is its ability to give richer background through links. It gives the LLM background that's deeper than keyword matches, telling it how pieces of information relate. This leads to more layered answers – it's the difference between knowing two facts separately and understanding that one is the cause or starting point of the other.
Graph RAG also handles hard, multi-step questions naturally. For questions that need thinking across multiple documents, the system can follow a chain of thought in the finding step itself. It basically does the thinking as a graph query, so the LLM gets the answer almost pre-built (it just needs to put it in plain words).
Perhaps most surprisingly, Graph RAG can use fewer tokens. By using summaries and focusing only on key parts of graphs, it can greatly cut down the amount of text fed into the LLM per question. One study showed Graph RAG getting the same or better answer quality while using just 2-3% of the tokens compared to a full summary approach.
Challenges
Like any high-level method, Graph RAG comes with challenges:
Hard Setup: Building the first knowledge graph from messy data is not easy and needs careful pulling out of things and their links. Mistakes in this step can hurt how well it works.
Graph Upkeep: In changing fields, the knowledge graph needs ongoing updates. If not kept up, the system could give outdated answers.
Speed Issues: Searching a graph and walking through it can be slower than a simple vector lookup, though this is getting better with better graph databases and fine-tuning methods.
Not Always Needed: For simple questions or small document sets, regular RAG might be enough. Graph RAG shows its value as question complexity grows or when bringing together diverse data sources.
Visualizing Graph RAG
To better understand how Graph RAG works, think about this flow from the original text:
"In Graph RAG, a user's question is turned into a graph query that finds key nodes (a 'starting point' in the knowledge graph) and expands to linked information, which is then returned as an organized result. The LLM combines this organized background with the question to make an answer. This way makes sure the found background isn't just fitting, but also linked, matching how the answer should be shaped."
A typical Graph RAG flow might look like this:
User question → Question processing
Question → Graph database (finding starting nodes)
Graph walking (expanding to related nodes)
Organized subgraph returned to LLM
LLM combines organized background with question to make answer
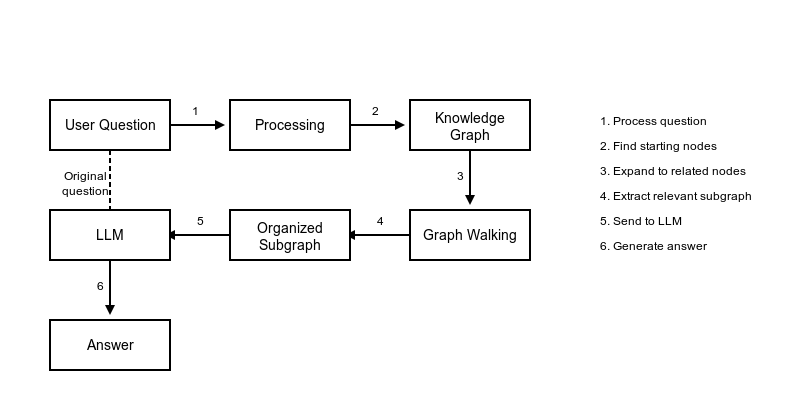
This process can be seen as a flow where the starting question spots key things in the knowledge graph, then follows link edges to gather related information before showing this organized background to the language model.
Conclusion
Graph RAG shows a strong step forward in how knowledge is fed to AI models. By bringing together the free-flowing brilliance of LLMs with the tight order of knowledge graphs, it gives the best of both worlds: smooth, context-aware answers that are based in factual links.
The shift in thinking is easy to grasp: people don't learn facts in isolation; they create mental maps of how things relate. Graph RAG lets AI do something like this by giving it a knowledge map, not just knowledge pieces. An LLM with Graph RAG support can tell not only what matters but why it matters, because the background it gets is filled with meaning.
For AI systems that need to handle hard questions or bring together diverse knowledge sources, Graph RAG is worth looking into. It's basically teaching AI to learn the oldest trick in human smarts: making links. And as many teachers would agree, that's when real understanding begins.
👏🏼
Great article 🤘